
Our next topic is yet more ways of collecting and organizing information, in other words, "data structures".
These notes cover similar material to chapter 11 in Zelle, so do read that.
It's not uncommon to find entire CS courses on just this topic ... but we can at least get started. 🙂
First, one more new built-in data type: what python calls a "dictionary", also called an "associative array" or "hash table" in other languages.
It's like an array, but with non-numeric "keys". The pairs of things in 'em are called (key, value) pairs. And there are lots of tricky methods built in.
jim = { "name" : "Jim", "age": 53 }
print("My name is ", jim['name'])
print("My age is ", jim['age']
# Look at dir(jim) to see all the methods like
# jim.keys()
# jim.items()
# jim.has_key(key)
# jim.get(key, value_otherwise)
# 'name' in jim # True if jim contains that key
Dictionaries are very useful data structures. In fact, the symbol table of a running program is essentially just a dictionary, with each variable's name and value. Objects are very like dictionaries, with "slots" for both data and methods. Most of the other CS data structures are things with specific uses built from lists and dictionaries.
In Javascript, the language used within all browsers to manipulate web page, dictionaries and objects are actually one and the same thing. And their syntax is almost the same.
To run javascript (sometimes called just "js") in a terminal, it's usually spelled "node" (go figure). Here's an interactive session.
mahoney@greymaple:~$ node # interactive javascript !
Welcome to Node.js v14.13.0.
Type ".help" for more information.
> person = {'name' : 'Jim', 'age': 61} # same syntax as python works !
{ name: 'Jim', age: 61 }
> typeof(person) # python has type() ... spelled different here
'object' # ... but it says it's an object !?
> person['name'] # Hmmm. This is the python dictionary syntax
'Jim'
> person.name # ... but this is the python object syntax !
'Jim'
So in javascript, objects and dictionaries are one and the same.
Both objects and dictionaries are abstractions that let us associate names with values. An object also has methods, which dictionaries do not. A dictionary is designed to modify the names and values while the program is running, while typically the names of the fields within an object don't change but are instead part of the object definition.
The reason that these are called "hash tables" has to do with how they are implemented. What's actually stored is a very large, probably mostly empty list. The key is put into a "hash function" which returns an integer, and that integer is used as an index to decide where in that big list to put its corresponding value. Check out this wikipedia hash table article to learn more.
The "name spaces" that we've been seeing, a list of variables and values that we keep track of when a function runs ... those are just essentially a dictionary.
Unlike lists, dictionaries are unordered ... which means that you cannot ask for the first element, and you cannot sort them. A dictionary is just a way to find a value given a key. If you want to sort the keys, you'd first put them into a list, then sort that list.
# Get a sorted list of the keys in a dictionary
keys = some_dictionary.keys()
keys.sort()
One thing dictionaries are good for is counting things, using key:count for each sort of thing.
For example, suppose we have this file of words named words.txt :
cat
dog
dog
cat
duck
elephant
mouse
mouse
dog
elephant
dog
dog
cat
cat
Then this will do the job.
"""
count_words.py
count the words in a file
(Note that both of these functions use the "accumulator" pattern
we've been using throughout the course.)
"""
def readfile(filename = 'words.txt'):
""" return list of words from file """
the_file = open(filename, 'r')
lines = the_file.readlines()
words = []
for line in lines:
words.append(line.strip()) # remove newline characters
return words
def countwords(wordlist):
""" return dictionary of {word:count} """
counts = {}
for word in wordlist:
if word in counts:
counts[word] = 1 + counts[word]
else:
counts[word] = 1
return counts
def main():
words = readfile()
dict = countwords(words)
print(dict)
main()
Running that in my terminal looks like this
mahoney@greymaple:Desktop$ ls
total 8
4 count_words.py 4 words.txt
mahoney@greymaple:Desktop$ python count_words.py
{'cat': 4, 'dog': 5, 'duck': 1, 'elephant': 2, 'mouse': 2}
For a more interesting example, check out this program to count the words in Moby Dick.
We now have these sorts of things which can store information :
These can be embedded within each other to create all sorts of containers for various kinds of information, depending on its internal structure.
An object such as a DeckOfCards could contain a list, and each element of that list could be another object such as a Card.
Reading in a file gives a list of lines, where each line is a string made up of characters.
A matrix (or an image, for that matter) can be though of as a two dimensional list of lists :
identity = [ [1, 0, 0],
[0, 1, 0],
[0, 0, 1]]
And if that was a big matrix of pixels, the value of each pixel might be
a (red, green, blue) tuple rather than just a number. Such an image could
be stored as a list of lists of tuples.
If we store the information for a person in a dictionary (like my first example at the top of these notes), then for many people we could use a list of dictionaries.
Or if we wanted to add information about someone's facebook friends, we might have a person be
sally = {'name': 'Sally', 'age':21}
bob = {'name':'Bob', 'age':88}
jim = {'name': 'Jim', 'age':61, 'friends':[sally, bob]}
sally['friends'] = [jim, bob]
Depending on the task at hand, and how we want to organize our information, there are many, many ways to combine these data types into various sorts of arrangements.
The last example actually brings up a new idea, which is almost outside the scope of this course ... but worth mentioning just the same.
The rest of thiw material is relatively advanced may be skipped on a first reading. But it does cover some important concepts, and can get you into trouble and at times lead to unexpected bugs.
It's possible to link together different pieces of data by putting references to one of them into another one. These references are sometimes called "pointers".
Practically speaking, a reference (or pointer) is usually stored as the address of some other thing, not an entire copy of the thing.
In the example code above, the type of jim is dict. It has a key, 'friends',
and the value of that key is a list. The first element of that key is sally
... which is another dictionary, like the person jim.
So sally is inside jim. Or is it?
Let's look at what's going on in pythontutor.com
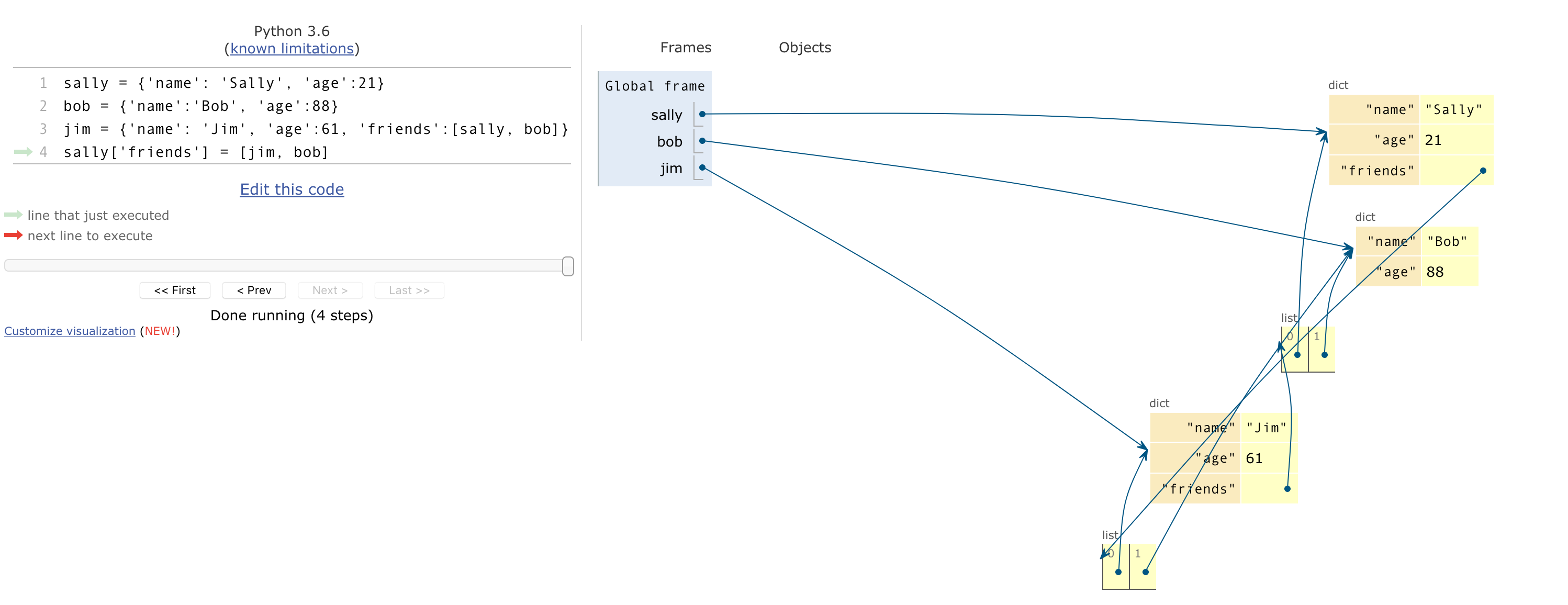
What we see is that these 'friends' lists actually contain pointers to
dictionaries, not duplicate copies of the dictionaries. So for example
even though sally['friends'][1] is bob, and jim['friends'][1] is also bob,
there is only one bob, not two different bobs.
Different languages handle these sorts of issues in different ways. And it isn't always obvious whether a pointer to some data is being set up, or whether a copy or the data is being created.
In python, some types of "small" data are typically copied (like numbers)
while other larger types of data (like objects and dictionaries) are
typically not duplicated unless a copy is requested in some way. Some
types of data may have a .copy() or .clone() method that does this;
for lists and dicts, you can use the built-in functions list and dict
to make a new copy.
These sorts of pointers are often used to build up graphs and trees, for example a family tree link this one. As a Python data structure, each Person here could be for an example an object, with a list of .parents , each of which could also be a Person object, arranged in a graph.
Python has an id built-in function which you can use to tell if two variables
point to the same underlying data. Here are a few examples.
>>> j = {'person':'Jim', 'age':61}
>>> k = j # this does NOT make a copy, just a name pointing to same data.
>>> id(j)
140646354742400 # same number, so same data
>>> id(k)
140646354742400
>>> new_j = dict(j) # new dictionary
>>> id(new_j)
140646354998336
Here's the pythontutor.com visualization of that code. Three variables, but only two data blocks ... both of which look the same.
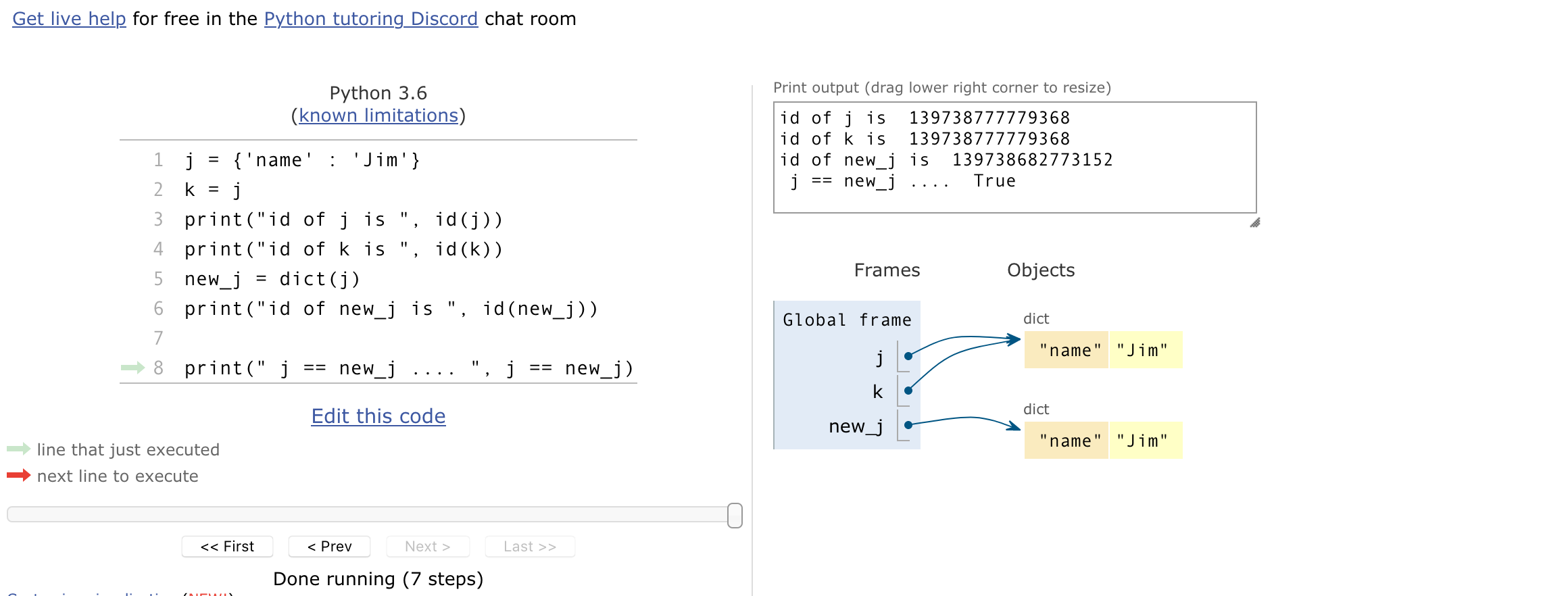
There is one more complication which I can't help but bring up as long as we've come this far, which you can see in that last image.
It turns out that in python, == is essentially True whenever the two sides look the same
when printed ... they do not need to have the same id's. So even though j and new_j are
different blocks of memory, since the print out the same the are == in python.
If you want to see if two things are in different blocks of memory, use id(), i.e.
id(a)==id(b). Python does have a built-in that is essentially the same as this,
namely a===b ... but it's an operator that I think leads to more trouble than
it's worth, and so encourage you to stick to == and id() if needed.
![[paper clip]](/courses_static/images/paper_clip_2.png)
| last modified | size | ||
| family_tree.png | Fri Oct 02 2020 01:09 am | 248K | |
| ids.png | Thu Oct 01 2020 11:43 pm | 197K | |
| pointers.png | Thu Oct 01 2020 11:18 pm | 294K |