
Questions about anything so far?
Volunteers for SEPC rep & alternate?
Note that my solutions to last week's homework is posted ... please check that out to compare with your work.
Today's notes cover a lot of ground - we'll likely not get through it all today, and continue on Thursday. Please do break in with questions when you need to.
This week the goal is to understand how we measure an algorithm's behavior. What makes one "good"? What does that even mean - easy? fast? small?
The basic ideas are
Often times there's a tradeoff between time and space ... we can find a faster method if we use more memory.
Explain O() with Skienna's chap 2 slides (pg 5+)
Note that knowing the O() behavior does not give us enough information to know the run time for a particular algorithm on a particular computer using a particular language. Even an O(1) (which we usually think of as fast) algorithm might take 10 years to run ... all that tells us is that the time does not depend on the size of N.
So how do we learn what what O() is for a given algorithm?
For a given problem? Answer: it's hard to know ... maybe we just haven't found the right algorithm.
One common theme we'll see is that we can if we're clever sometimes replace an O(n) loop-through-the-list with an O(log n) divide-by-halves approach, which can make a huge difference in efficiency. The general version of this approach is often called "divide-and-conquer"; we'll see several examples in the coming weeks.
Here's an example of several O() algorithms for the same problem : is_anagram(word1, word2)
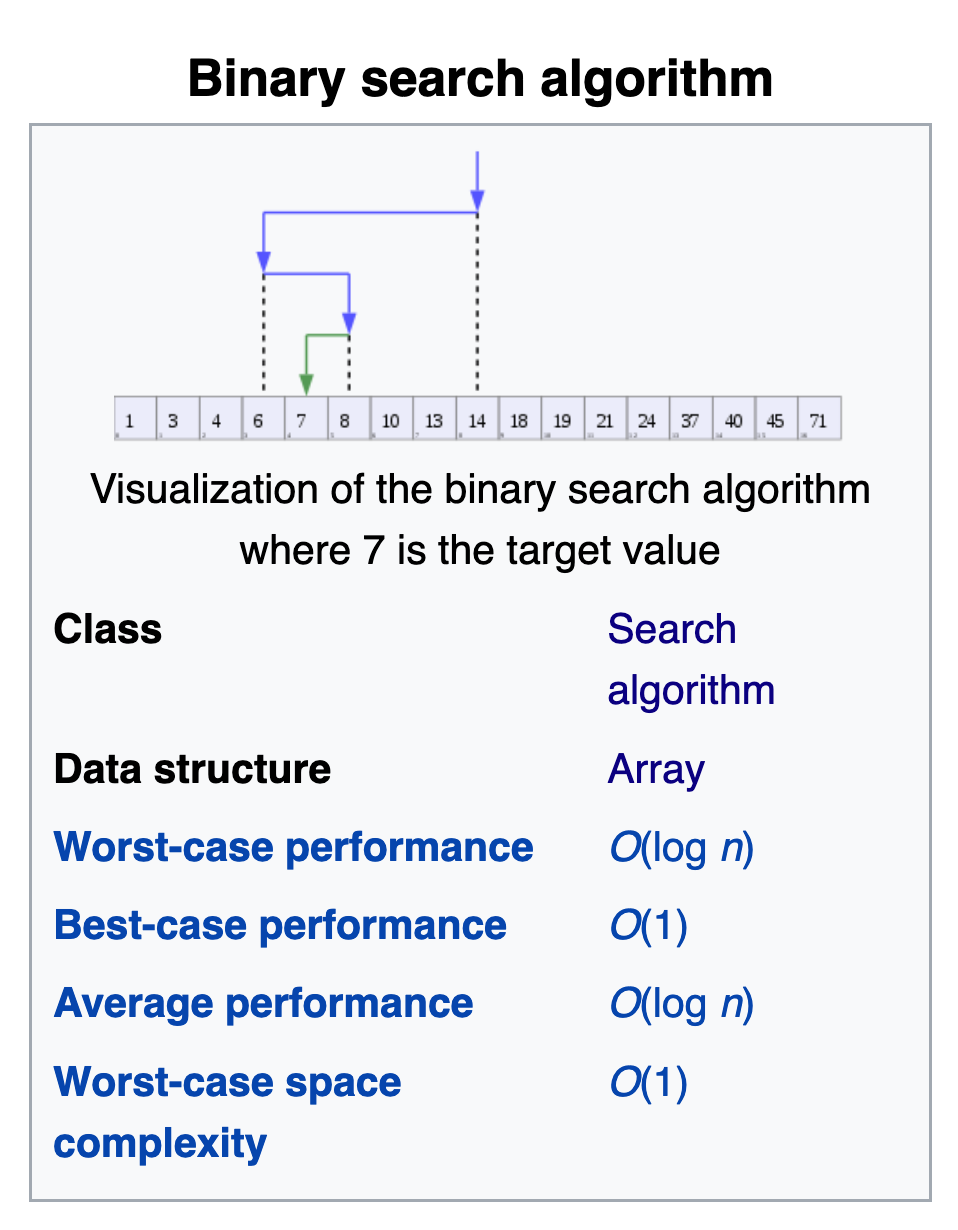
Another example is binary search , which is one way way to look for a value in an indexed array. (Quick quiz: what is another way to look for a value in a list? What is it's O()? Why not always use binary search?)
We'll look at some python code and a jupyter notebook numerical experiment for this binary search example in just a bit.
Which algorithm is "best" may depend also on how many times operation will be repeated, or memory requirements, or how much preparation is needed. If for example you want to search for one person given a million of them, you might
O(n log(n)) and then do repeated binary search ( O(m log n) for m repetitions, orTurns out that in practice, there's a big difference between exponential algorithms (2^N, N!, ...) and polynomial (n**2, n log(n), ...) algorithms. I'm oversimplifying, but the exponential ones are in general too slow for any sizes that aren't tiny. Problems whose known algorithms are exponential are considered "hard".
This is actually at the heart of one of the best known unsolved theory problems in computing, known as P vs NP, where "P" are those problems that can be solved in polynomial time (i.e. O(poly)), while "NP" is a class of problems where we only know of exponential time algorithms like O(2N) ... but cannot prove that maybe we just aren't clever enough to find faster algorithms.
Let's talk through this whole "log" (log2(n), log10(x), ...) thing, just to make sure we're all on the same page with this math.
See for example khan academiy.
And we'll be visualizing numerical data with plots (jupyter python notebook, numpy, matplotlib) ... like these plotting examples .
The O() issues also come up when counting various sorts of things. For example, what O() are each of these counting operations?
For a few examples of log scale consider the following :
Let's take a closer look at the "linear search" and "binary search" examples with some explicit code, and discuss : array_search_numerical_experiment .
This is the sort of "numerical experiment" that I've asked you to do for homework this week. Feel free to reuse and/or adapt any parts of this code. (And if so, as always, reference your sources.)
We're going to look the O() behavior for various operations for data structures containers : arrays, lists, dictionaries, etc.
Typically there are tradeoffs; you cannot optimize for all types of operations such as (add data, remove data, search for data, get smallest data, merge data, etc).
Use those data structures as components in recipes for specific problems : searching, graphs, ...
Find common ideas in different algorithms: brute-force, divide-and-conquer, greedy, dynamic-programming, ...
Next week : a few common data structures, revisited.
Coming : sorting ... lots of different ways.